
实存
内存管理,又称实存管理
共性:用户进程需要全部进入内存,除非用户提供覆盖技术
实存管理分为连续(单一、固定、可变)和可离散(页式、段式、段页式)
地址空间
逻辑地址空间和物理地址空间
程序和数据执行前需存储于内存。为管理方便,用户编写的程序和最终执行的代码位于不同的地址空间(逻辑地址和物理地址)
程序从编写到执行
- 编辑
- 编译:二进制模块
- 链接:二进制模块连接库函数等,变为装入模块
- 装入:将装入模块装入内存
- 执行
计算机常使用的 3 类地址
- 符号地址:存储变量名、函数名等,符号地址空间或名空间
- 逻辑地址:目标代码所使用地址从 0 开始编号,相对地址
- 物理地址:绝对地址,实地址
地址变换和内存共享及保护
重定位:将逻辑地址转化为物理地址
- 静态重定位:装入时一次性完成地址转换
- 动态重定位:边执行边进行地址变换,程序在内存中可移动
内存共享:多个进程通过一个物理内存区域进行通信的方式,常见共享方式如下
- 生产者 - 消费者
- 可重入代码:纯代码,执行期间不改变(只读,由 OS 实现),可共享,如编辑软件、编译软件、运行时库、窗口系统、数据库系统等
内存保护
- 存取控制保护:读、写、执行操作权限控制,如
chmod 777 nmsl.txt - 地址越界保护:确保每个程序只能访问其所属内存地址空间,保护其他程序正常执行
- 上下界寄存器:分别表示用户程序内存地址空间的最小 / 大地址,在执行时与之比较,超出范围
[x,y]则报错 - 基质 / 重定位寄存器和界限寄存器:记录内存最小值和程序长度,访问时通过
[x,x+len]进行判断
- 上下界寄存器:分别表示用户程序内存地址空间的最小 / 大地址,在执行时与之比较,超出范围
内存的分配和回收
内存分配和回收:内存分为系统区和用户区,系统区放 OS,用户区放用户程序
- 分配和回收,以及多道程序,其操作对象一般都是用户程序,均工作在内存用户区
碎片:存储分配中无法利用(容量太小,没有利用价值)的内存空间
- 内部碎片:分配给用户程序的用户空间中没有被占用、也不允许其他程序占用的空间。固定大小的存储分配可能导致内部碎片,如固定分区、页式管理、段页式管理等
- 外部碎片:用户区剩余的、无法利用的存储空间。非固定大小的存储分配可能导致外部碎片,如动态分区、分段存储分配等
连续分配管理方式
为用户程序分配连续的内存空间,使得用户程序的逻辑地址相邻,则物理地址也相邻
特点
- 整体性,用户程序全部装入内存(覆盖技术可允许部分装入)
- 不支持虚拟存储器
- 作业运行结束才释放所占空间
连续存储管理方式:单一连续分区;固定分区;可变分区
分区分配管理
单一连续分区
单一连续分区:内存用户区最多存放一个用户程序,属于计算机早期的存储方式
- 静态分配,管理简单
- 存在内部碎片;存储器利用率低(单道);无法实现多道程序共享内存;仅适用于单用户单任务操作系统
固定分区
固定分区:用户区事先划分为多个分区,每个分区最多可存放一个用户程序,是最早、最简单的可运行多道程序的分区式存储管理模式
- 各分区大小可以相等,也可以不等
- 当大小相等:适用于一台计算机控制多个相同对象的场合
- 当大小不等:灵活性更高,通常划分为多个较小分区、适量中等分区、少量的大分区;一般来说小分区位于物理地址的小地址端,大分区反之
- 使用数据结构分区使用表管理各个固定分区,记录各个分区的分区号、容量、编号、起始地址和状态信息等,都是事先规定且不能更改的
- 在使用时,OS 首先查询分区使用表,查不到能用的则拒绝执行进程
- 比较所需内存和分区内存大小
- 查询分区状态,是否已装入
- 特点:事先划分分区,每个分区装一个作业;多个分区并发执行;采用静态重定位技术装入内存
- 可用于多道程序系统,可采用覆盖技术,利用率较高
- 存在区内部碎片,且需要考虑各任务干扰问题,需要内存保护
可变分区
可变分区:将用户区分为若干分区,分区的大小、个数可灵活变化
空闲分区表:每个空闲分区(空闲或未分配)占一个条目,在空闲分区表中,相邻空闲取需要合并
空闲分区链:一个双向链表,将所有空闲分区连接起来,其节点信息类似于
struct node{ node* pre; // 前驱 node* next; // 下一条 int mem_size; // 分区大小 int status; // 0 为空闲,1 为已分配 }1
2
3
4
5
6
分区管理方式(单一、固定、可变分区)均使用界地址保护内存
动态分区分配算法
首次适应算法
首次适应算法
- 空闲分区表按首地址递增排列,顺序查找,直到找到大小满足的空闲分区
- 找到后,根据作业所需大小分配该空闲分区,多余的部分仍存在空闲分区表中(修改相应表项)
- 未找到,分配失败
循环首次适应算法
循环首次适应算法:从上次找到的空闲分区的下一个分区开始,寻找符合的内存区域,找到后分配出和作业所需大小一样的内存
- 减少查找开销,避免低地址区存在很多很小的空闲分区
- 造成大分区分得比较小,不利于大作业装入
最佳适应算法
最佳适应算法:空闲分区按容量大小递增排序,每次找到最小的符合作业大小的分区并分配内存
- 贪婪思想的表现,每步均为最佳
- 可能产生许多难以利用的小空闲区,宏观上不一定最佳
最差适应算法
最差适应算法:空闲分区按容量大小递减排序,每次分配时将最大的满足作业的分区进行分隔,降低剩余空间
- 分配后的空闲区较大,便于下次使用
- 后期不利于大作业装入
快速适应算法
快速适应算法:又称分类搜索算法,将内存空间大小相同的空闲分区分为一类,并将同类分区通过双向链表相连,同时建立一张分类表索引,记录各类分区的表头指针;当查找分区时,找到最适合的类(最小的大于)的第一快空闲分区进行分配
- 回收空间的算法复杂;一个分区一个进程,同样会造成区内空间浪费(连续性分配管理的通病)
伙伴系统
伙伴系统:将内存分为一个个2^k大小的块,并将2^n块分配个各个作业
- 设初始状态为 1024 MB,首次接收到一个需要 100 MB 的作业,分出 128 MB 的内存块给这个作业,剩下内存从大到小进行分割
- 从大到小指剩下的 896 MB 依次分为 512 MB、256 MB、128 MB
- 每次接收到之后都会进行这样的分割,伙伴系统将相同大小的块进行分类管理(以快速适应算法的形式管理)
在为作业寻找内存块时,假设所需 n MB,且2^(k-1) <= n <= 2^k
- 需要明确的是,肯定要找比 n 大的内存块,即从 2^k MB 开始找
- 若存在,直接分配
2^k的内存块 - 若不存在,继续往大了找,找到后,从大的内存块中分
2^k给该进程,剩下的空间分成一个或多个2^k大的内存块,插入链表
若一直找到最大内存的记录,链表均为空,则分配失败
散列算法
Hash 散列,以HashMap<内存大小,内存块链表指针>的形式记录内存块,查找时从 map 中直接查找即可
分区分配动态管理
为了解决连续分配产生的很多无法分配的细碎小空间,通过拼接 / 紧凑,移动内存中的作业,使之邻接,再将内存中分散的小空闲合并成大空闲分区实现
这一过程需要进行进程的动态重定位,通过重定位寄存器实现,存储进程在内存的起始地址,在实际寻址时,通过相对地址和寄存器中的起始地址求和得到
页式管理
非连续存储管理:页式管理;段式管理;段页式管理
地址映射
非连续分配又称为离散分配管理,将进程的逻辑地址分为若干等大区域,称为逻辑页、页面或页,从 0 开始编号,通过页表进行管理
- 页空间过大会造成最后一个页空间浪费较大(只有进程的最后一个页才会出现区内空间浪费)
- 页空间过小会造成页表过长
物理空间中,也将物理地址分为一个个大小与页面相等的内存块,与页一一对应,用于存储进程的各个页面
在这种管理方式下,逻辑地址格式为:页号位 + 页内偏移量位(参考计组知识)
单级页表
页表:索引结构,从上往下依次是逻辑页 0, 1, ... , n-1 对应的物理块号和存取控制权限,访问时,根据逻辑页号读取对应的物理块号
| 块号 | 存取控制 |
|---|---|
| 1000 | RWE |
| 50 | RWE |
| ... | ... |
| 2000 | RWE |
| ... | ... |
| 600 | RWE |
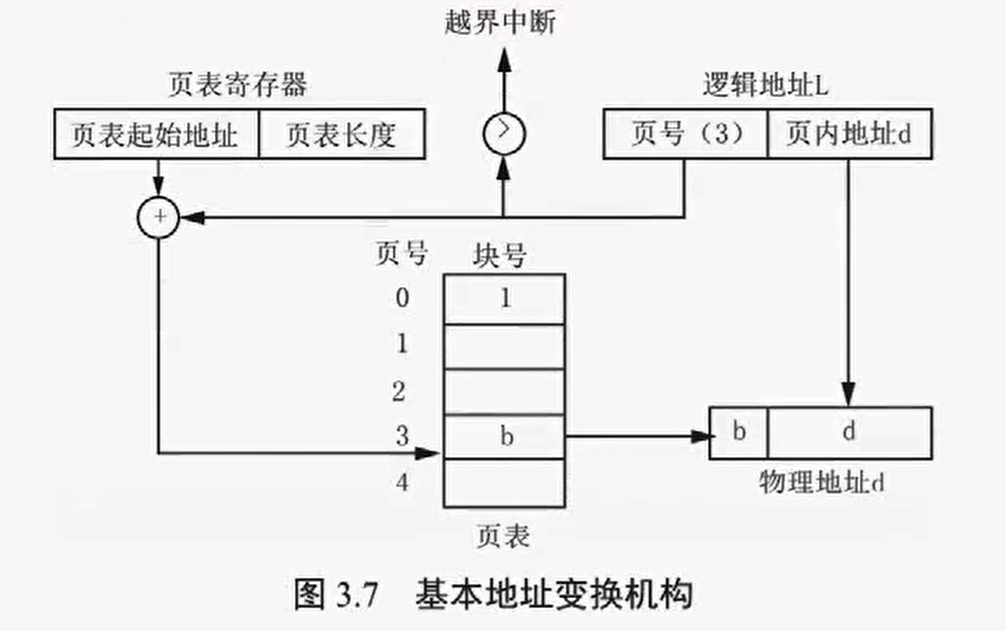
地址变换借助页表实现,将逻辑地址的页号转换为内存的物理块号。同时设置有页表寄存器(PTR),记录页表的起始位置和长度帮助基本地址变换机构查询
查询流程
- CPU 访问 PTR,找到进程对应页表
- 根据逻辑页号找到对应的物理块号
- 块号和页内地址的二进制拼凑成实际物理地址
- 块号通过逻辑地址第一段查询页表得到
- 页内地址由逻辑地址第二段提供
- 访问实际物理地址存取数据
常见的两种基本地址变换机构
查询页表
增加快表,先查询快表 TLB,若无再查询页表
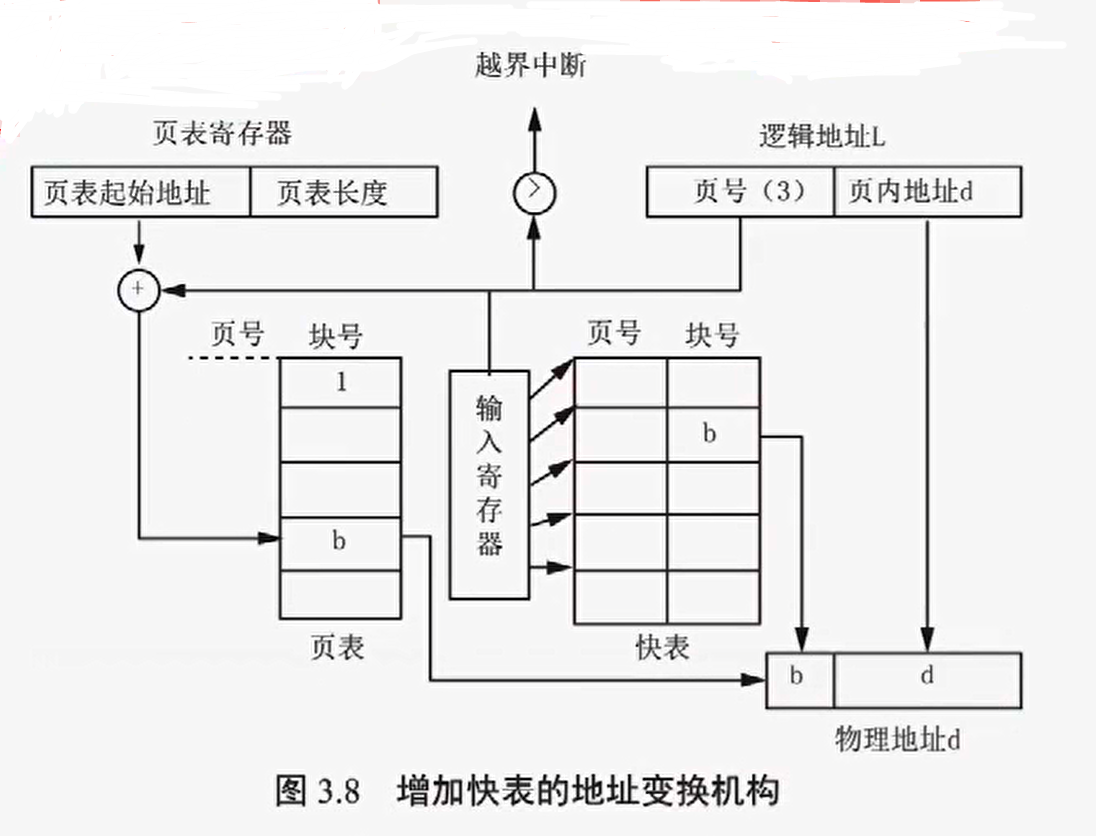
这里涉及到一个访问时间的问题,由于页表常驻内存,访问页表算一次访问内存时间,同时访问物理地址数据也算一次访问内存
设访问内存时间为 T,访问快表(缓存)时间为 t,则存/取一次数据,所需时间
- 基本地址变换机构:2T
- 增加快表的地址变换机构:[λt + (1-λ)(T+t)] + T = (2-λ)T + t
分级页表
现代计算机系统地址位数大多为 32/64 位,这意味着逻辑地址空间在2^32~2^64,页表极大,且要占连续内存空间,于是采用分级页表解决页表过大问题,常见的有:二级页表、三级页表、反置页表
对于 32 位计算机,逻辑地址空间2^32B,设一个内存块大小为4KB(2^10),若采用单级页表,将会有2^22个页面,即页表有2^22行(4MB)
二级页表
二级页表:将整个单级页表分为若干个独立页表进行储存
适用于 32 位计算机 —— 设页内空间2^12,二级页表将整个 20 位的页表分为两部分,外层页号 P1 和外层页内地址 P2,各占 10 位
- 外层页表 10 位,存储 1024 个页表项,每一项指向一个外层页内地址
- 外层页内地址 10 位,存储 1024 个页表项,每一项指向一个进程块号
外层页内地址即指针数组,指向一个个进程块号,外层页表同样是指针数组,指向的对象是一个个指针数组的起始位置
- 外层页表 —— 页表的页表
- 指针所占的总空间其实增加了,但拆分的更细,占用连续空间更小(将数组拆分为链表)
- CPU 首先通过外部页表寄存器查找外部页表
二级页表最终通过外层页内地址找到块号 b 后,和逻辑页内地址 d 拼接成内存物理地址
共需三次访问内存(多一次页表访问)
- 第一次:访问外层页表
- 第二次:访问外层页内地址
- 第三次:访问内容
如何减少二级页表下的内存开销?
- 不将外层页内地址全部存放在内存中,即部分存放在外存
- 将外层页表每项增设状态位,记录其对应外层页内地址是否在内存中
- 实际访问时,若状态位位 1,直接访问内存中的外层页内地址,若不在,产生中断调入内存
多级页表
开始套娃,适用于 64 位计算机,分为 20 位 P1,15 位 P2,15 位 P3,最终通过 P3 得到物理块号 b,和 14 位的页内地址 d 拼接成物理地址
反置页表
不同于记录逻辑地址指针,对应物理块号;反置页表记录的是物理块所存放的逻辑页页号和所属进程标识
- 逻辑页号 ——> 物理块号:在每个进程的表中:primary key = 逻辑页号
- 物理块号 ——> 进程号 + 逻辑页号:primary key = 物理块号
检索时,搜索的时进程号和逻辑页号,找到了,其序号就是物理块号;若没找到,说明逻辑页未装入内存,需要请求调用(虚拟存储器)
其他非连续存储管理
段式管理
页,按容量管理,克服页外碎片,最后一个页可能存在业内碎片
段式管理,以程序的功能逻辑为单位进行内存分配,将作业地址空间分为若干段
- 每个段具有标识
- 每个段的段内一定连续,段间可不连续
- 作业装入时整个装入
优点
- 便于编程,如按函数和过程划分
- 便于共享,如共享
printf函数 - 便于分段
- 动态链接
- 动态增长
进程的段式管理的逻辑地址格式:段号 + 段内地址
- 表示该进程最多分为段号位个段,每个段大小最多为段内地址位
段式管理通过段表(常驻内存或放在寄存器)对段进行管理,每个进程有一个映射段表,每个段在段表中占一行,下标为段号,每行包含段长和段起始位置
- 段号一定要小于段长(段表长度)
和单级页表类似,每访问一次数据需要两次访问内存,可以通过增设快表 TLB 加快访问
段页式管理
若段内功能过于复杂,可能导致段过大,于是采用段页式管理,先进行分段,再在段内进行分页
地址格式
- 逻辑地址分为:段号 + 页号 + 页内地址
- 段表每行记录:页表长度,页表起始位置
- 页表每行记录:下标为页号,内容为物理块号
查询过程:共三次读内存
- 查段表,根据段号读取页表,得到页表长度及起始位置
- 查页表,根据页号获取物理块号
- 根据块号拼接页内地址获取物理地址,访问数据
