单选(2/30)
1.算法能识别出错误的输入数据并进行适当的处理和反应,称为算法的()
- A. 健壮性
- B. 正确性
- C. 并行性
- D. 时间复杂度
2.从一个具有 n 个结点的单链表中查找其值等于 x 的结点时,在查找成功的情况下,需要平均比较的节点个数是()
- A. n
- B. n/2
- C. (n-1)2
- D. (n+1)2
3.设有一个双端队列,元素进入该队列的次序为 abcd,则既不能由输入受限双端队列得到,也不能由输出受限双端队列得到的输出序列为()
- A. dbca
- B. dcba
- C. dbac
- D. dcab
4.下列关于串的叙述中,正确的是()
- A. 一个串的字符个数即该串的长度
- B. 空串是由一个空格字符组成的串
- C. 一个串的长度至少是1
- D. 若两个串S和S的长度相同,则这两个串相等
5.对一棵满二叉树,m 个树叶,n 个结点,深度为 k,则()
- A. k+m = 2n
- B. n = k+m
- C. n = 2k-1
- D. m = k-1
6.一个具有 10 个顶点的有向图中,所有顶点的入度之和与所有顶点的出度之和的差等于()
- A. 20
- B. 5
- C. 0
- D. 2
7.对于线性表 (7,34,55,25,64,46,20,10) 进行列存储时,若选用 H(K)=K%9 作为散列函数,则散列地址为1的元素有()个
- A. 1
- C. 3
- B. 2
- D. 4
8.采用贪心算法不能求解的问题是()
- A. 0-1背包问题
- B. 活动安排问题
- C. 找零钱问题
- D. 背包问题
9.用数组Q[m]存放循环队列的元素,rear 和 len 分别表示该队列的队尾元素的位置和队列的长度,则队列第一个元素的位置是()
- A. rear-len
- B. (rear+m-len) % m
- C. m-len
- D. rear-len+m
10.线性表若采用链表存储结构时,要求内存中可用存储单元的地址()
- A. 必须是连续的
- B. 部分地址必须是连续的
- C. 一定是不连续的
- D. 连续不连续都可以
11.在头指针为 head 且表长大于 1 的单循环链表中,指针 p 指向表中某个结点,若p->next->next = head,则()
- A. p 指向头结点
- B. p 指向尾结点
- C. *p 的直接后继是头结点
- D. *p 的直接后继是尾结点
12.快速排序在最坏的情况下的时间复杂度是()
- A. O(log2n)
- B. O(nlog2n)
- C. O(n^2)
- D. O(n^3)
13.设某棵三叉树中有 45 个结点,则该三叉树的最小高度为()
- A. 3
- B. 4
- C. 5
- D. 6
14.设 n 个元素进栈的序列是 1,2,3,...,n,其输出序列是 (p1,p2,...,pn),若 p1 = 3,则 p2 的值()
- A. 一定是1
- B. 一定是2
- C. 可能是1
- D. 可能是2
15.在长度为 n 的顺序表的第 i (1≤i≤n+1) 个位置上入一个元素,元素的移动次数为()
- A. n-i+1
- B. n-i
- C. i
- D. i-1
判断(1/15)
1.链式栈与顺序栈相比,一个明显的优点是通常不会出现栈满的情况()
2.在一个顺序存储的循环队列中,队头指针指向队头元素的位置()
3.数组一旦建立,结构中的元素个数和元素间的关系就不再发生变化。因此,一般都采用链式存储的方法来表示数组()
4.从串中取若干个字符组成的字符序列称为串的子串()
5.一个无向图的邻接矩阵中各元素之和与图中边的条数相等()
6.具有 6 个顶点的无向图至少有 6 条边才能确保是一个连通图()
7.顺序表的特点是:逻辑上相邻的元素,存储在物理位置也相邻的单元中()
8.线性表的各种基本运算在顺序存储结构上的实现均比在链式存储结构上的实现效率要低()
9.在散列法中,中个可用的散列函数必须保证绝对不产生冲突()
10.在任何情况下,快速排序方法的时间性能总是最优的()
11.一个问题是否具有最优子结构性质是该问题是否可以用动态规划法求解的重要前提()
12.层次结构设计方法有两种:自顶向下和自底向上()
13.数据结构与算法的本质联系表现在失去一方,另一方将没有任何意义()
14.二叉树是一棵无序树()
15.对于一棵具有 n个结点的任何二叉树,进行先序、中序或后序的任一种次序遍历的空间复杂度为 O(logn)()
填空(2/30)
1.()是数据的基本单位,即数据这个集合中的一个个体
2.数据的逻辑结构分为两大类:()
3.Huffman 树共有()个结点,n 为叶子结点个数
4.设一棵完全二叉树中有 500 个结点,若用二叉链表作为该完全二叉树的存储结构,则共有个空指针域()
5.设不含头节点的链队列中结点的格式为(data,next),front 为其头指针,rear 为其尾指针,则该队列为空的条件是()
6.已知一个栈的输入序列为 1,2,3,...,n,则其输出序列的第 2 个元素为 n 的输出序列的种数是()
7.对于一维数组A[15],若一个数组元素占用字节数为 s,则A[i](i>0)的存储地址为()
8.无向图中的极大连通子图称为该无向图的()
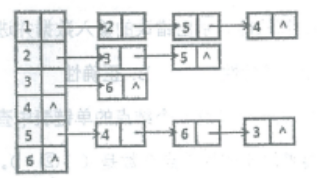
9.已知图G的邻接表如下图所示,其从顶点 1 出发的深度优先搜索序列为()
10.单链表表示法的基本思想是用()表示结点间的逻辑关系
11.设 r 指向单链表的最后一个结点,要在最后一个结点之后插入 s 所指的结点,需执行的三条语句是(); r = s; r->next = null;
12.一个顺序表的第一个元素的存储地址是 200,每个元素的长度是 2,则第 6 个元素的地址是()
13.除留余数法选择一正整数 p,以关键字除以 p 所得的余数作为散列地址,通常选 p 为()
14.某个散列函 H 对于不相等的关键字 key1 和 key2 得到相同的散列地址(即H(key1 = H(key2)),则将该现象称为()
15.二分搜索中查到每一个记录的比较次数可通过折半查找判定树来描述,那么查找某个结点进行的比较次数即为被查找结点在树中的()
问题求解(45)
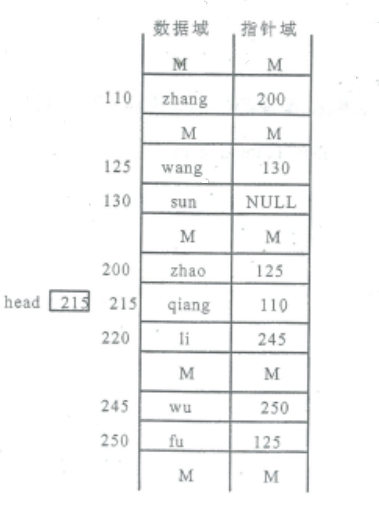
1.(7分) 下图是一个单链表的每个结点的物理位置的示意图,请用一般图示法画出该单链表
2.(7分) 假设二维数组A[][8],每个元素用相邻的6 个字节存储,存储器按字节编址,已知A的基地址为 1000,计算
- (1) 数组A的占用的存储空间
- (2) A 的最后一个元素第一个字节的地址
- (3) 按行存储时,
A[1][4]的第一个字节的地址 - (4) 按列存储时,
A[4][7]的第一个字节的地址
3.(7分) 设有一组初始记录关键字为 (45,80,48,40,22,78),要求构造一棵二叉排序树并给出构造过程
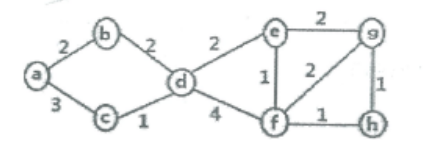
4.(8分) 对下列连通图(如下图所示),请分别用 Prim(从定点 a 出发)和 Kruskal 算法构造其最小生成树
5.(8分) 假设用于通信的电文由十种不同的符号来组成,这些符号在电文中出现的频率为 8,21,37,24,6,18,23,41,56,14,试为这十个符号构造哈夫曼树,并设计相应的哈夫曼编码(要求树中左孩子结点的权值小于右孩子结点的权值)
6.(8分) 对于下列一组关键字 46,58,15,45,90,18,10,62,试写出快速排序第一趟的一次划分过程,并写出每一趟的排序结果
算法设计(30)
1.(10分) 设计算法求关键字 x 在二叉排序树中的层次
int lev=0;
typedef struct node{
int key;
char data;
struct node *Ichild,*rchild;
}bitree;
void level(bitree *bt, int x){
/* 在此作答 */
}
2
3
4
5
6
7
8
9
10
11
2.(10分) 请在空格处将算法补充完整。完成下面的算法,识别一次读入的一个以@为结束符的字符序列是否为形如序列1&序列2模式的字符序列。其中序列 1 和序列 2 中都不含字符&,且序列2是序列 1 的逆序列。例ab&ba是属该模式的字符序列而1+3&3-1不是
typedef struct{
SElemType data[M];
int top;
}*Stack;
Push(Stack ST,SElemTypex); // 已定义的入栈操作
Pop(Stack STSElemType x); //已定义的退出栈顶元素赋给x的操作
BOOL Symmetry(char a[]){
int i=0;
// 定义栈 s
Stack s;
InitStack(s);
ElemType x;
while(__①__ && a[i] != '@'){
__②__;
i++
}
if(__③__) return FALSE;
i++;
while(a[i] != '@'){
__④__;
if(__⑤__){
DestroyStack(s):
return FALSE;
}
i++;
}
return TRUE;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
3.(10分) 已知一个顺序表,编写算法,实现在其值为 x 的元素之后插入 m 个元素的算法
int InsertM(sequenlist *L, int x, int m){
} //InsertM
2
3